GlidedSky 爬虫挑战-字体反爬1
六月 03, 2020
GlidedSky 爬虫挑战-字体反爬1
实验环境
- Python 3.8.1
- Pycharm 2019.3
相关依赖
- requests(发送http请求)
- BeautifulSoup(document解析)
- fake-useragent(伪装请求头)
- fontTools(解析字体)
实现过程
1. 网页分析
待爬网页介绍
http://www.glidedsky.com/level/web/crawler-font-puzzle-1
字体文件本质上是从字符到图像的一个映射。比如字符0,浏览器会从字体文件当中找到0这个字符对应的图像,然后展示出来。
如果字符0展示并不是0的图像是1的图像呢?这也就意味着爬虫拿到的是字符0,但是人看到的却是图像1。
因此只需要找出网页显示的字体文件,并找出其映射关系即可解决此种反爬问题
实际显示效果如下,可以看出由于字体映射关系的改变,爬虫可直接获取的源代码显示与实际显示完全不同
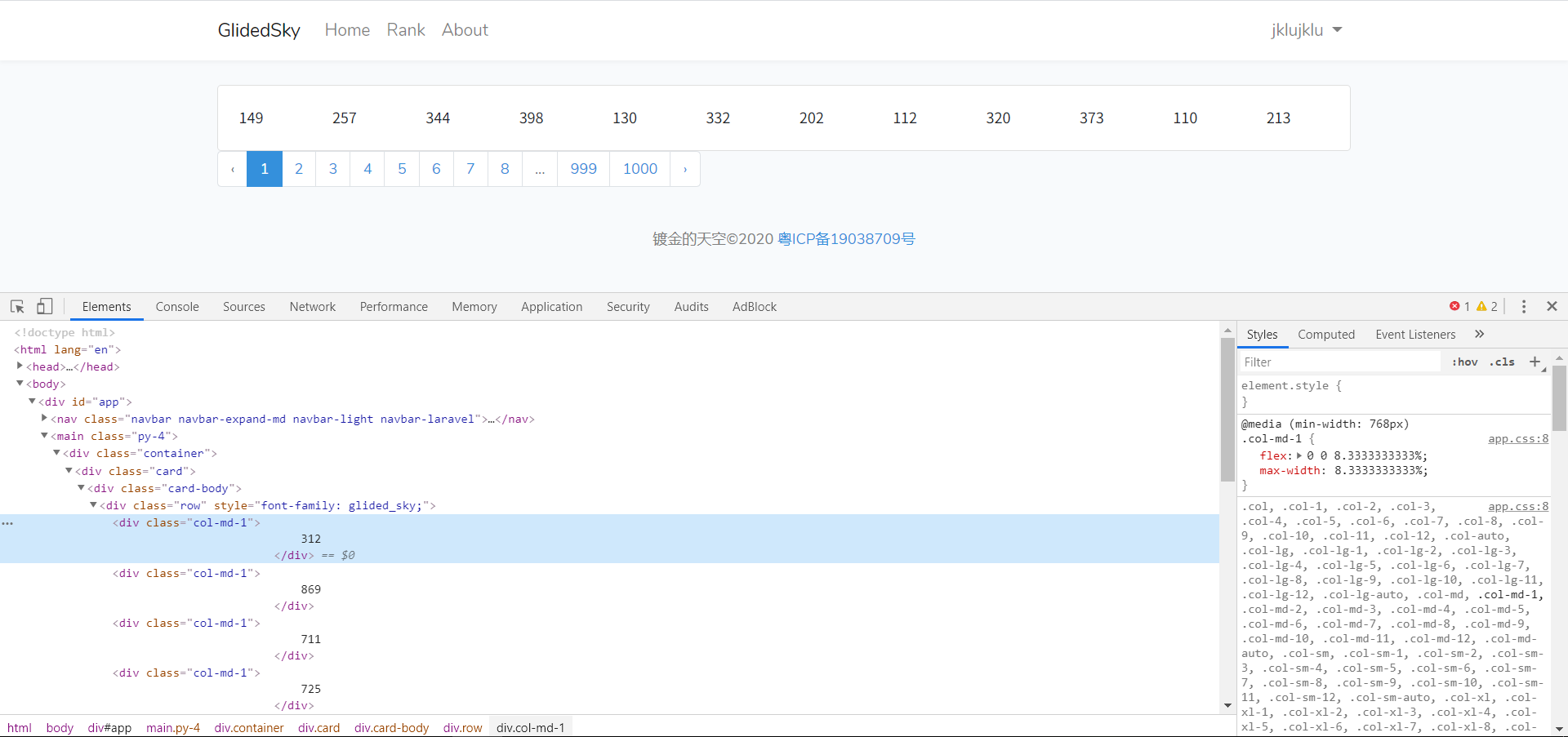
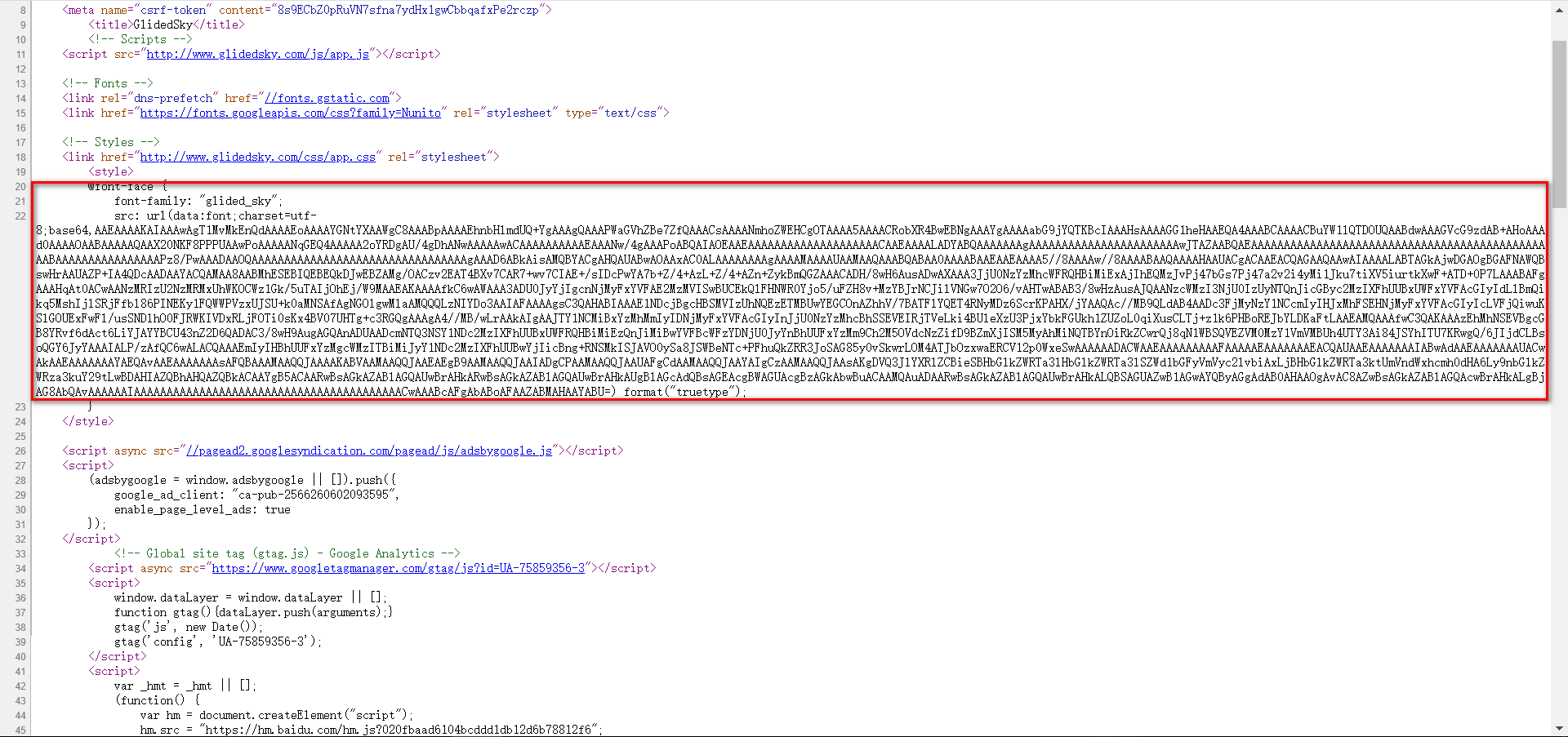
分析源代码,可以看到这个网页的字体经过base64编码已经内嵌到html中,因此,只需要将base64解码,即可获得字体内容,但字体内容为二进制流,单纯的解码能看到的只有乱码,因此还需要将解码数据写入到本地,将其保存为.ttf字体文件
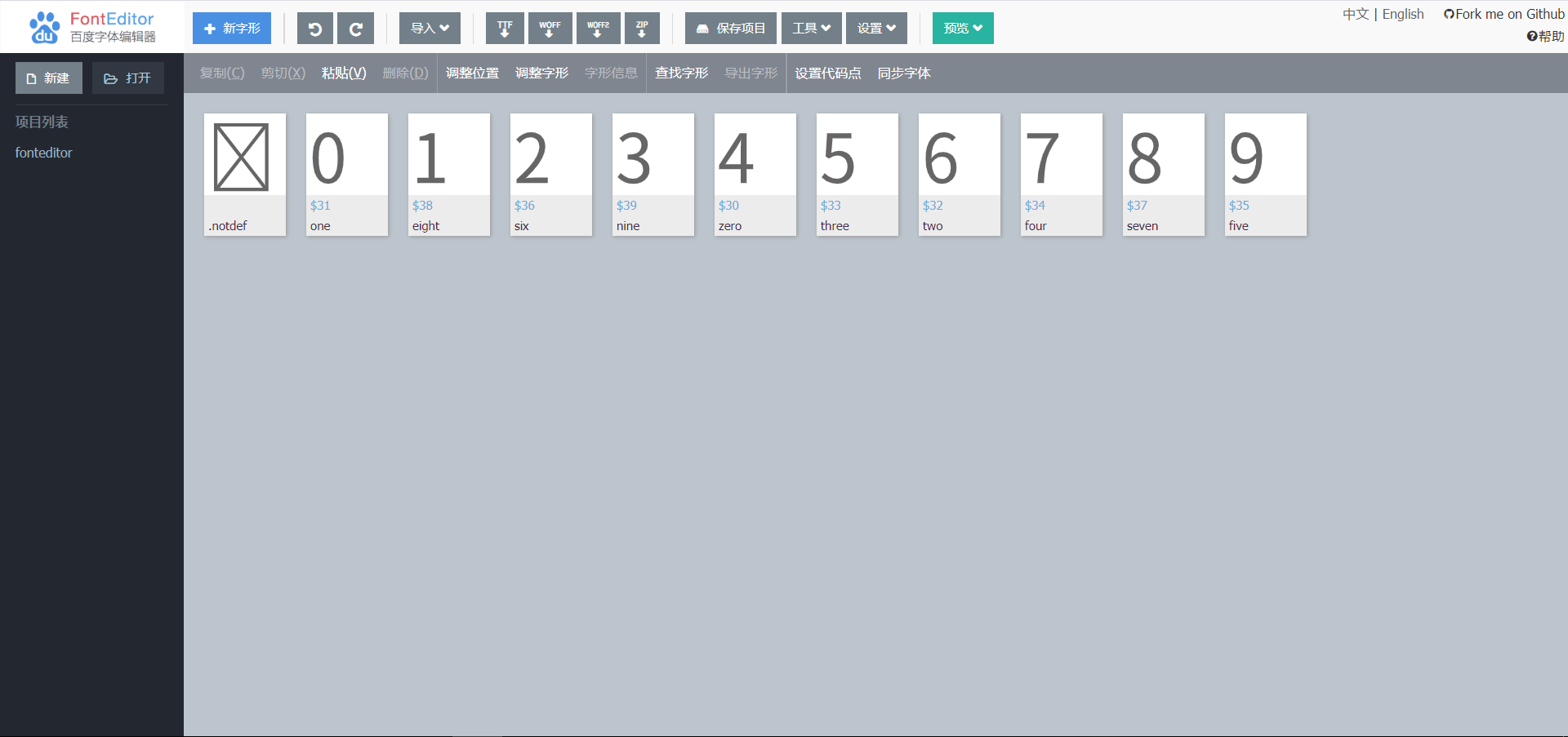
将下载下来的字体,在字体编辑器中打开,即可看到真正的字符映射
通过fontTools包,将下载下来的字体转化为xml(此步骤功能与上一步一致)
1
2
3from fontTools.ttLib import TTFont
font = TTFont(font_file) # 打开本地的ttf文件
font.saveXML('59.xml')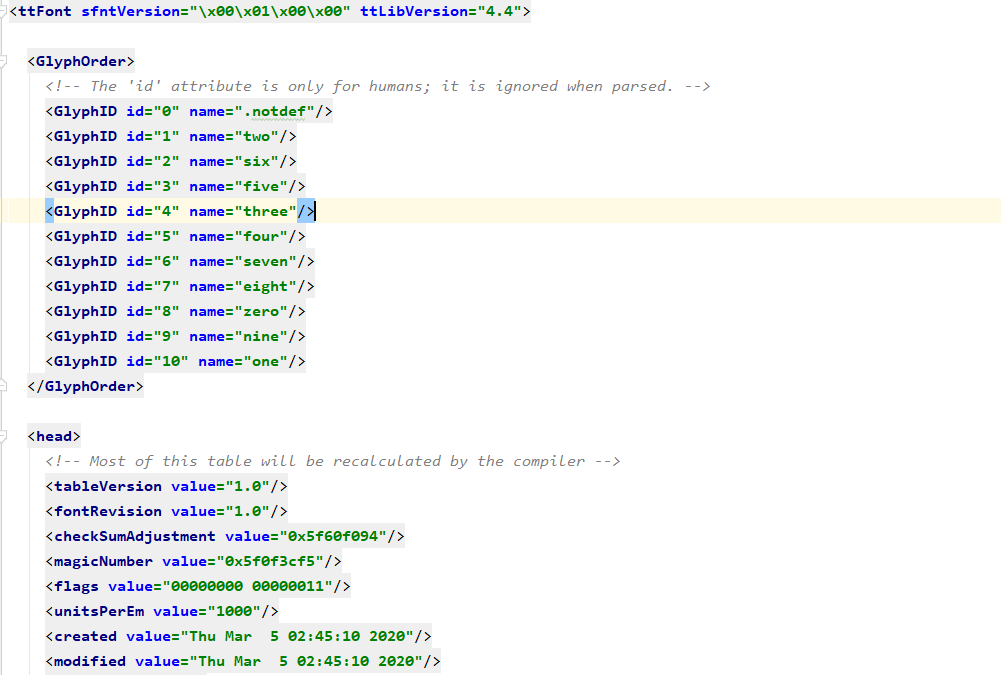
P.S:以上2个步骤仅为测试字体文件,实际实现无需此步骤
- 根据得到映射关系,将源代码中数字进行映射即可得到真正的值
2. 主要代码
主函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def parseHtml(html):
"""
解析html文档,获取自定义base64字体编码,同时进行解密
:param html: 待解析html
:return: 当前html中数字的和
:rtype: int
"""
global decodeEntry # 存放实际映射关系
# 正则匹配获取base64编码
pattern = re.compile('base64,([^\)]+)')
matchobj = re.search(pattern, html)
# 获取实际映射,结果存到decodeEntry中
decodeEntry = getEncodeEntry(downloadFont(matchobj.group(1)))
# bs解析网页,获得所有加密的数字
bs = BeautifulSoup(html, "html.parser")
# <div class="col-md-1"> 321 </div>
elements = bs.find_all(class_="col-md-1")
sum = 0
for i in elements:
# 获取元素内容,即数字
digital = i.get_text().replace(" ", "").replace("\n", "")
# 将数字累加,得到总和
sum += eval(decodeNum(digital))
# print(decodeNum(digital))
# 返回当前页面的数字总和
return sum
字体下载函数
1
2
3
4
5
6
7
8
9
10
11
12
13def downloadFont(font_encode):
"""
下载base64字体文件
:param font_encode: base64字体编码
:return: 字体文件名称
:rtype: string
"""
# 将base64解码
b = base64.b64decode(font_encode)
# 写入文件
with open('01.ttf', 'wb')as f:
f.write(b)
return "01.ttf"
获得实际映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def getEncodeEntry(font_file):
"""
获取字符映射关系
:param font_file: 自定义字体文件
:return: 加密字符的映射关系
:rtype: dict
"""
font = TTFont(font_file) # 打开本地的ttf文件
font.saveXML('59.xml')
# 获取GlyphID,内容见上方图片,返回的时GlyphID标签中的name属性
bestcmap = font.getGlyphOrder()
entry = {}
# 获取0-9每个数字的映射
for i in range(10):
entry.update({bestcmap[i + 1]: str(i)})
return entry
参考文章
查看评论